Learned Image Compression
Traditional image compression standards have been developed over more than 30 years. In contrast, with the rapid advances in neural networks, learned image compression (LIC) has demonstrated superior coding performance compared with traditional image compression standards. Two representative LIC networks proposed in CVPR 2020 and CVPR 2023 are presented below.
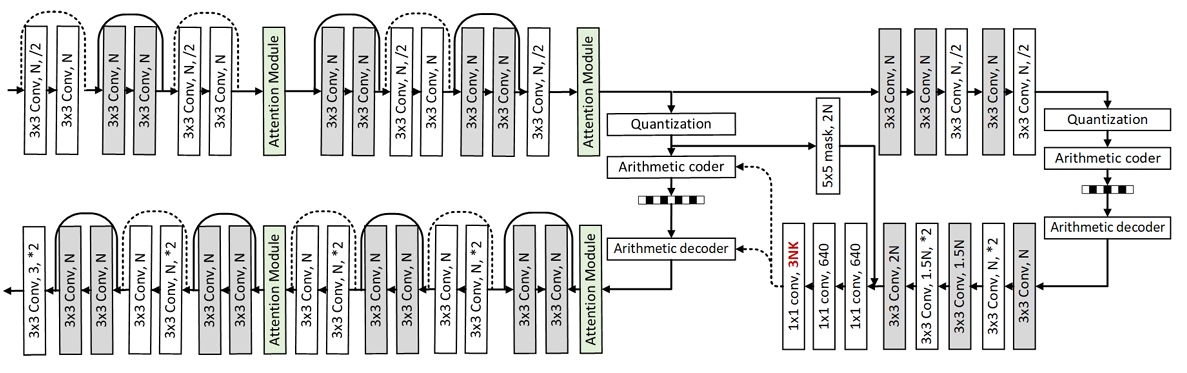
We proposed a LIC model incorporating a Gaussian mixture model (GMM) and attention mechanisms, achieving state-of-the-art performance in 2020.
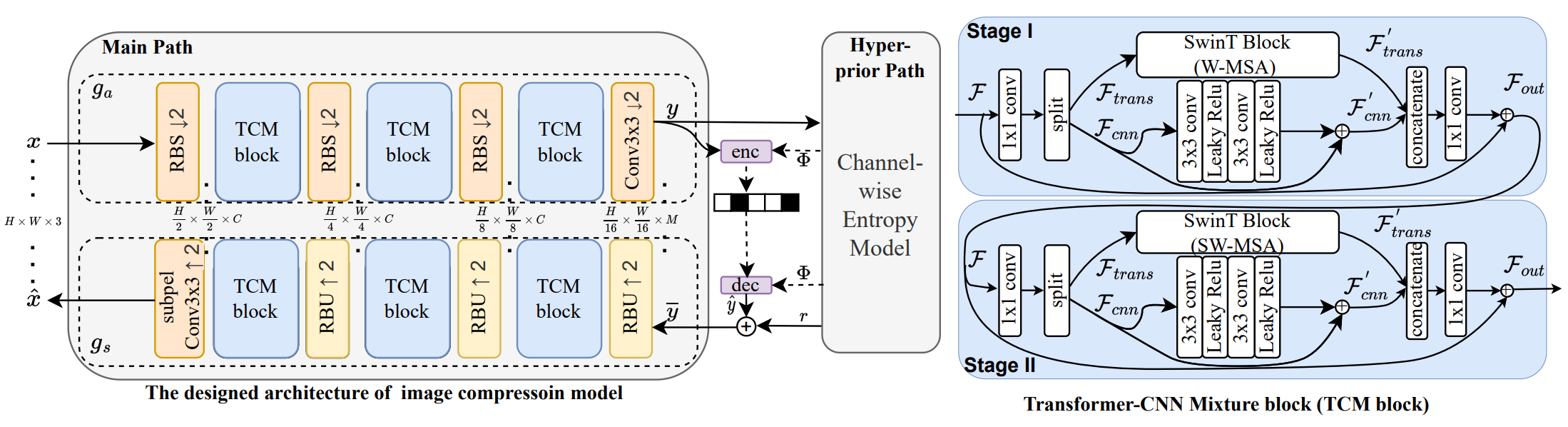
We proposed a LIC framework that combines transformer and CNN architectures, achieving state-of-the-art performance in 2023.
Learned Video Compression
Traditional video compression standards have also been developed for over 30 years. Similar to image compression, learned video compression (LVC) has demonstrated superior coding efficiency compared with traditional video compression standards. The proposed LVC network (CVPR 2025) is shown below.
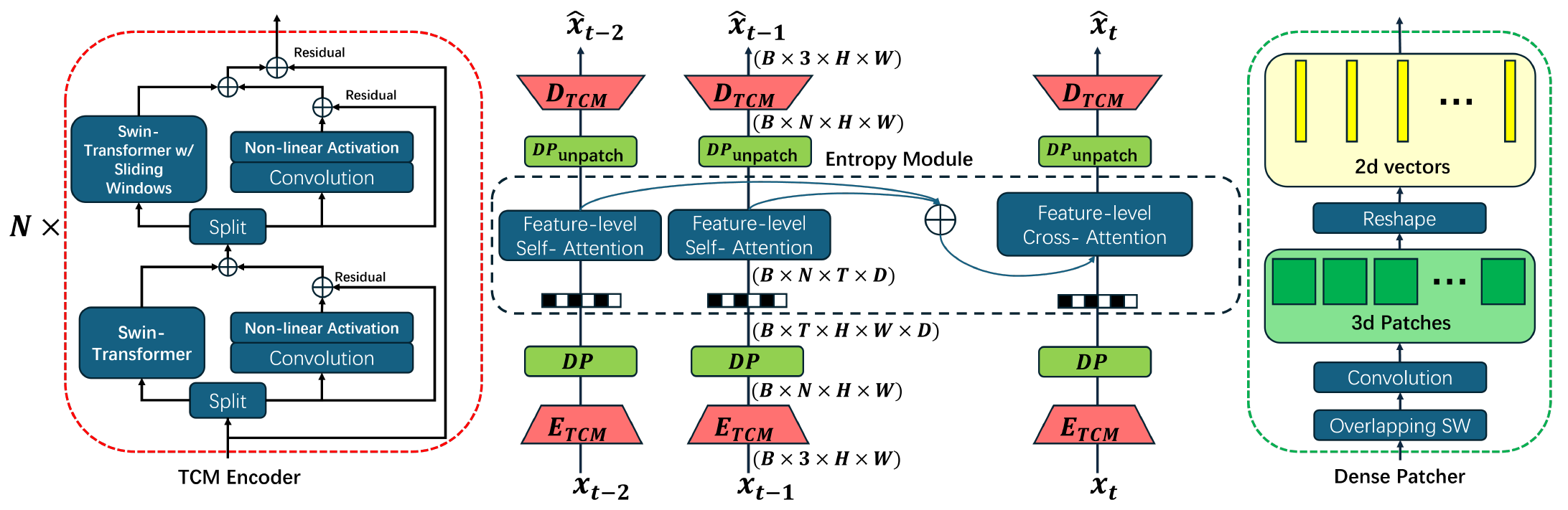
Proposed LVC with feature level attention.
Image Coding for Machine
Cisco has reported that machine-to-machine communication will account for up to 50% of all network traffic in the forthcoming IoT society. Consequently, reducing the transmission burden between machines has become increasingly important. Unlike human-oriented visual coding, image coding for machines aims to improve the accuracy of machine vision tasks, such as object detection and tracking.
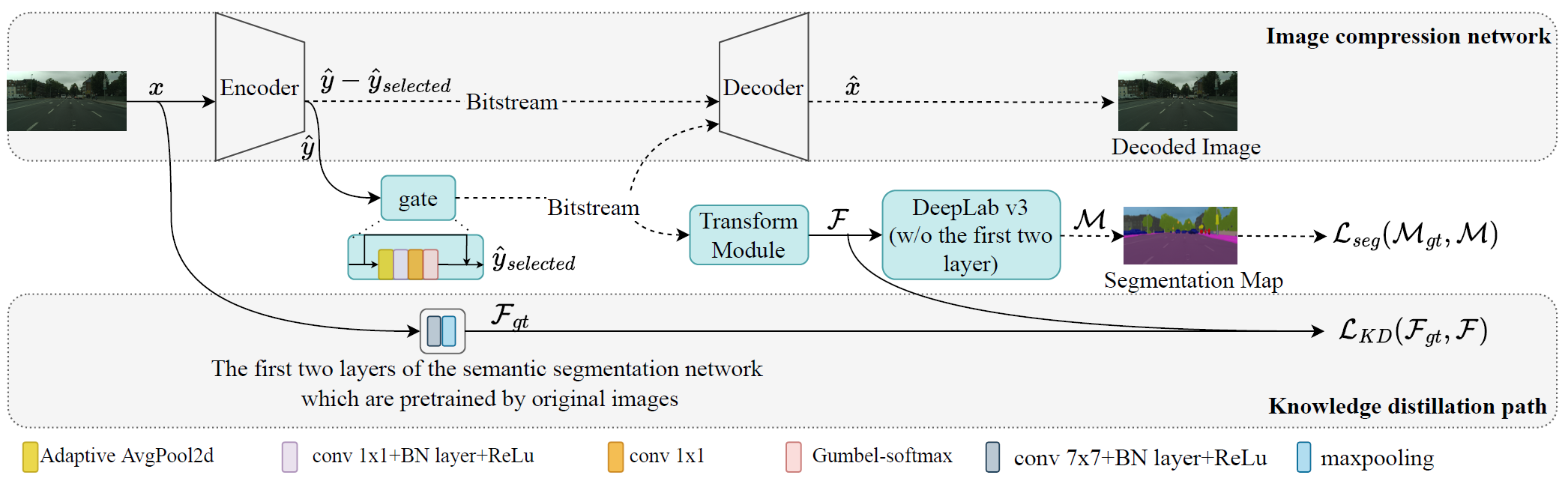
Proposed semantic segmentation in learned compressed domain
FPGA-Based LIC Systems
Among various hardware platforms, FPGAs offer higher hardware utilization and superior power efficiency compared with CPUs and GPUs. In addition, relative to ASICs, FPGAs provide greater flexibility and reconfigurability, enabling them to adapt to the rapid evolution of neural network models. Leveraging these advantages, we developed an FPGA-based neural engine with a fine-grained pipeline architecture and applied it to the LIC system.
A camera (bottom right) captures raw video at 720p and 30 fps, which is displayed on the right monitor. The captured video is then encoded by a Xilinx VCU118 FPGA board. The resulting bitstream is transmitted to a second FPGA board for decoding. Finally, the decoded video is displayed on the left monitor.
To evaluate the system latency, real-time timestamps are embedded and captured during processing. The difference between the original (raw) timestamp and the decoded timestamp is defined as the end-to-end latency, which is approximately 560 ms. In addition, a power meter is used to measure the actual power consumption of the entire FPGA board.
The encoder is implemented on a Xilinx VCU118 FPGA board, while the decoder is implemented on a Xilinx KU115 FPGA board. The video is correctly decoded and displayed on the left monitor, demonstrating the cross-platform coding capability of the proposed system.
ASIC Chip Design
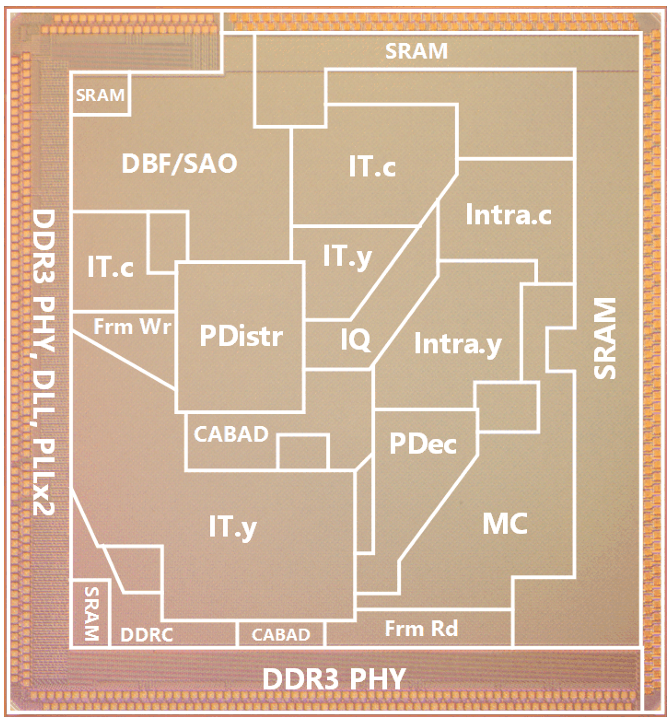
Developed an 8K@120 fps HEVC decoder chip, in which I was responsible for the inverse transform (IT) and dequantization (IQ) modules.