学習型画像圧縮(Learned Image Compression: LIC)
従来の画像圧縮標準は、30年以上にわたって開発されてきました。一方、ニューラルネットワークの急速な進展に伴い、学習型画像圧縮は、従来の画像圧縮標準と比較して優れた符号化性能を示しています。以下に、CVPR 2020 および CVPR 2023 にて提案された代表的な LIC ネットワークを示します。
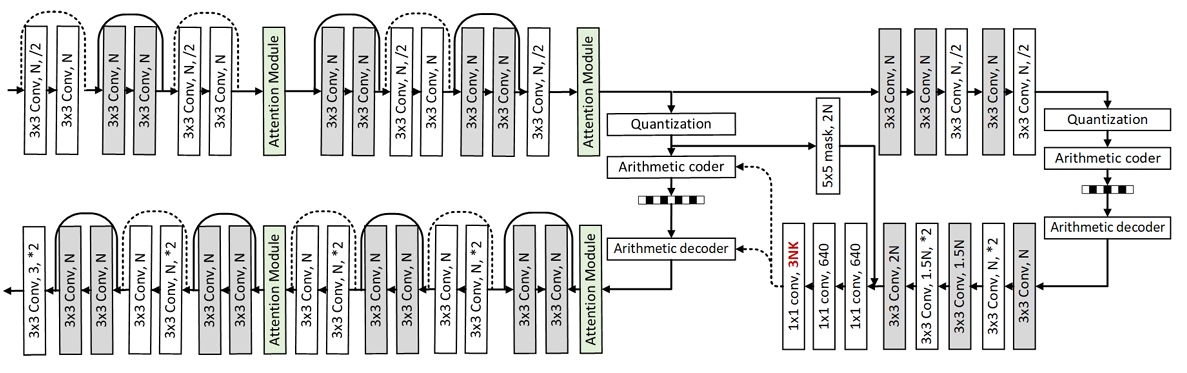
我々は,ガウス混合モデルと注意機構を組み込んだ学習型画像圧縮モデルを提案し、2020年において最先端性能を達成した。
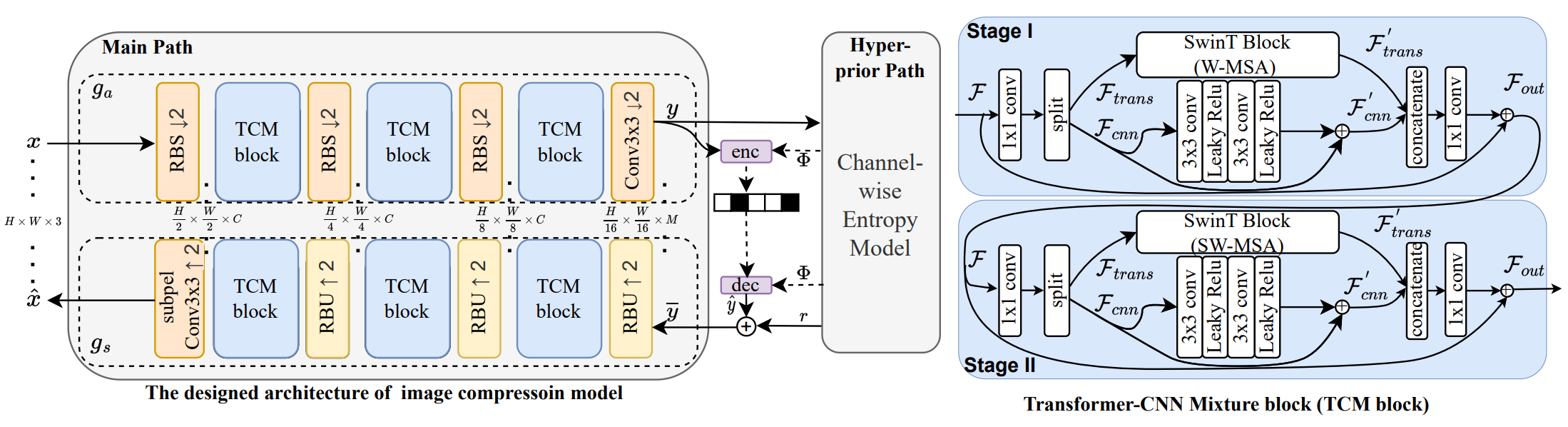
我々は,TransformerとCNNを融合した学習型画像圧縮フレームワークを提案し、2023年において最先端性能を達成した。
学習型動画像圧縮(Learned Video Compression: LVC)
従来の動画像圧縮標準は、30年以上にわたって発展してきた。画像圧縮と同様に、学習型動画像圧縮は、従来の動画像圧縮標準と比較して優れた符号化効率を示している。以下に、提案する学習型動画像圧縮ネットワーク(CVPR 2025)を示す。
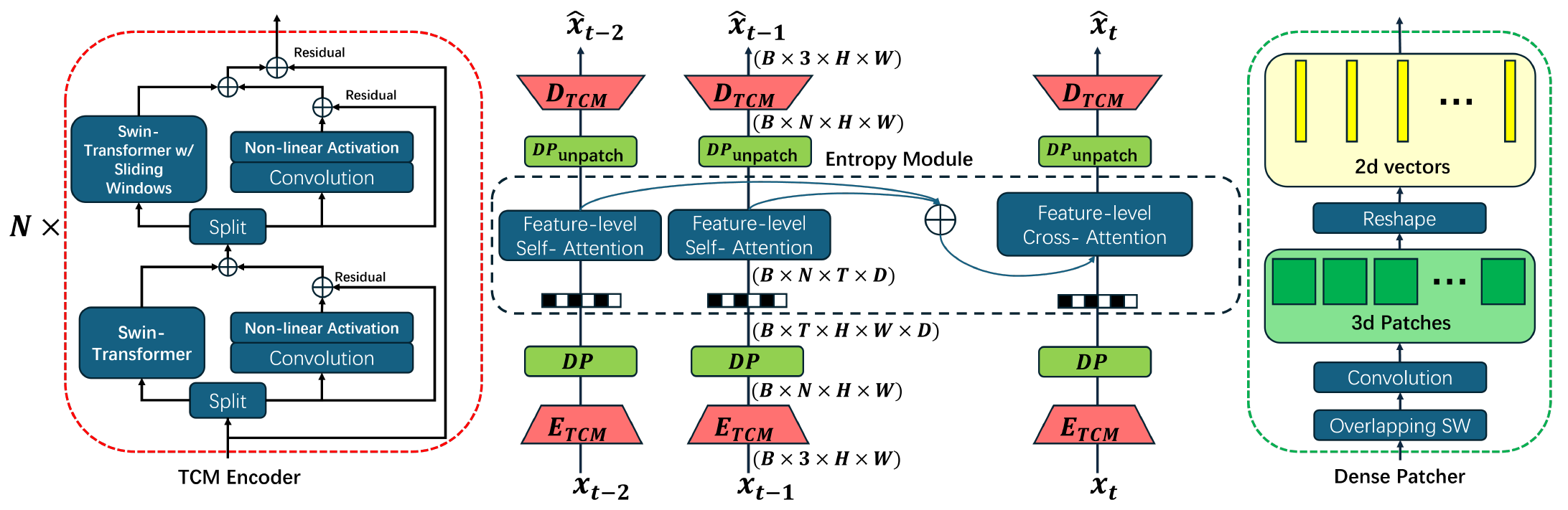
特徴レベル注意機構(Feature-level Attention)を導入した学習型動画像圧縮(LVC)
マシン向け画像符号化(Image Coding for Machines)
Cisco の報告によると、将来の IoT 社会において、マシン・ツー・マシン(Machine-to-Machine:M2M)通信は、全ネットワークトラフィックの最大50%を占めると予測されています。そのため、機械間通信における伝送負荷の低減は、ますます重要になっています。人間向けの視覚符号化とは異なり、マシン向け画像符号化は、物体検出や追跡といった機械視覚タスクの精度向上を目的としています。
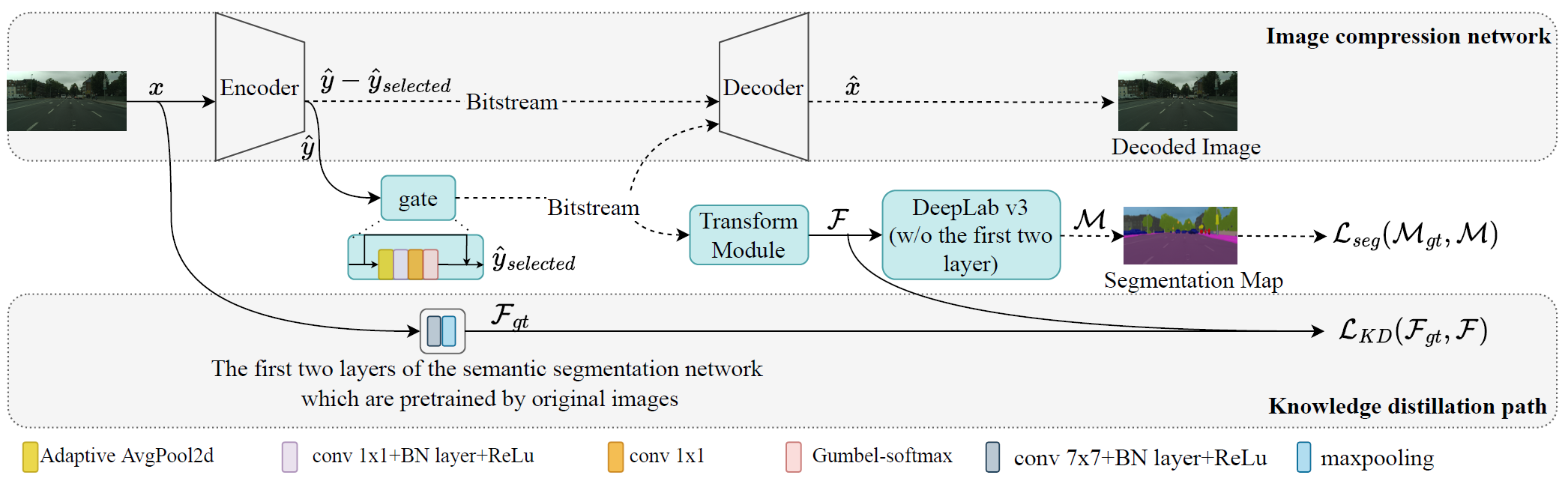
学習型圧縮ドメインにおける意味セグメンテーションの提案
FPGA ベース学習型画像圧縮(LIC)システム
さまざまなハードウェアプラットフォームの中で、FPGA は CPU や GPU と比較して高いハードウェア利用率と優れた電力効率を有しています。また、ASIC と比べて柔軟性および再構成性に優れており、ニューラルネットワークモデルの急速な進化にも対応可能です。これらの利点を活かし、我々は微細粒度パイプラインアーキテクチャを備えた FPGA ベースのニューラルエンジンを開発し、学習型画像圧縮(LIC)システムに適用しました。
右下のカメラで 720p・30 fps の生動画を撮影し、その映像を右側のモニタに表示します。撮影された映像は、Xilinx VCU118 FPGA ボードによって符号化されます。生成されたビットストリームは、別の FPGA ボードに送信され、そこで復号されます。最後に、復号された映像が左側のモニタに表示されます。
システム遅延を評価するため、処理過程においてリアルタイムのタイムスタンプを埋め込み、これを取得しています。元の(生映像の)タイムスタンプと復号後のタイムスタンプとの差をエンドツーエンド遅延と定義しており、その値は約 560 ms です。さらに、電力計を用いて FPGA ボード全体の実消費電力を測定しています。
エンコーダは Xilinx VCU118 FPGA ボード上に実装され、デコーダは Xilinx KU115 FPGA ボード上に実装されています。映像は正しく復号され、左側のモニタに表示されており、提案システムのクロスプラットフォーム符号化能力を実証しています。
ASIC チップ設計
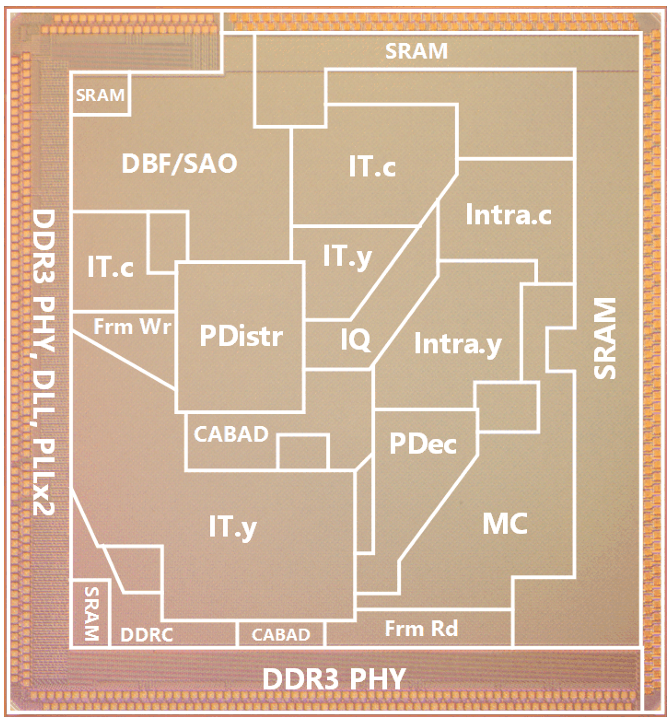
8K・120 fps 対応の HEVC デコーダチップを開発しました。私は、その中で逆変換(Inverse Transform:IT)および逆量子化(Inverse Quantization:IQ)モジュールを担当しました。